Nov 8 : Game Tree Search
Code discussed in lecture
Finish up Instant Insanity from last lecture.
Playing Games of Strategy on the Computer
There are three basic approaches for programming strategy games like Nim or Chips or chess or checkers. These games are called "games of perfect information", because both players know everything about the state of the game (unlike poker, bridge, and other card games, where you know your cards but not your opponent's). They also have no random or chance elements like backgammon or monopoly, where one rolls dice.
A Simple Strategy
The first is to come up with a strategy. This is a set of rules that tells you how to decide on your next move. For some games there is a simple strategy that will allow you to win if a win is possible.One such game is called Nim, where you start out with n sticks in a pile. On each turn you are allowed to take between 1 and k sticks. The person who takes the last stick wins. This game has a simple strategy based on the quantity (k+1). If n is a multiple of k+1 the second player can always win. If the first player takes m sticks, the second player takes k+1-m sticks to get to the next smaller multiple of (k+1). Thus when we get down to 1*(k+1) the second player takes the last stick.
However, if n is not a multiple of (k+1) then the first player takes enough sticks to leave a multiple of (k+1) sticks in the pile. This player now follows the second player strategy described above. In this case the first player can always wins.
Games that have a simple strategy are not very interesting to play. Fortunately there are many interesting games like chess where no such simple strategy is known.
Game Tree Search
The second approach is game tree search. This is the classic approach used for playing checkers, chess, kalah, Connect 4, and similar board games. It tries all moves for the first player, all responses for the second player, all third moves for the first player, etc. building up a game tree. We will discuss this approach for most of the rest of this lecture and part of the next. Your last assignment asks you to write a game tree search program to play Connect 4. (Connect 4 is 4-in-a-row tic-tac-toe played on a 7x6 board. However, it has gravity. When you play in a column the checker falls until it hits the bottom of the board or the top checker in that column.)Unfortunately, the game tree search approach is hopeless for go and other games with huge branching factors. (Go has 361 possible first moves, 360 replies to each of those, etc.) It also does not deal well with games that incorporate randomness, like bridge or backgammon.
Monte Carlo
The third approach is Monte-Carlo simulation. To decide what move to make it simulates thousands of random games that start from the current position and it computes for each possible move the percentage of the games that started with that move that ended up as wins. It chooses the move that had the best winning percentage. This seems like a stupid approach, but if enough games are played it works reasonably well. This web page has a demonstration program that uses this approach to play Connect 4. It doesn't do a bad job, but my Connect-4 program beats it regularly. It occasionally does things like not seeing that its opponent has 3 in a row and will win on the next move if it does not block.There is a more sophisticated method called Monte-Carlo Tree Search that combines the two approaches. The strongest go and bridge playing programs use this approach. This paper gives a two-page overview of the method for those who are interested. It is an area of current research.
Note that this approach can easily deal with random events like die rolls or imperfect information like hidden cards. For random events it simply simulates them as they arise in the game. For hidden information it generates a random layout at the start (e.g. a random deal for bridge) and then simulates the game on that layout.
Game Tree Search and Chips
In CS 5 we asked students to write a referee program for a variant of Nim called Chips. It is called this because the game starts with a pile of n poker chips. There are several versions. In one the first player takes between 1 and n-1 chips. For each subsequent turn the player can take between 1 and twice the number of chips that the player's opponent took on the previous turn. The winner is the player who takes the last chip, just as in Nim. If there is an easy strategy for playing this game we don't know it. This makes it a more interesting game, and a candidate for game tree search.
The first step conceptually is to create the "game tree" of all possible games from the given position. The diagram below shows the game tree for Chips starting with 4 chips in the pile. On the first move it is possible to take 3, 2, or 1 chips. Each of these leads to a different game state. If you take 3 chips then there is only 1 chip left, so you opponent must take it. If you take 2 chips there are 2 chips left, and your opponent can choose to take 1 or 2 chips. If you take 1 chip there are 3 chips left, and by the rules of Chips your opponent can take 1 or 2 of them (at most double what you took last move). It is tedious, but in principle you could draw the entire game tree for any game of perfect information.
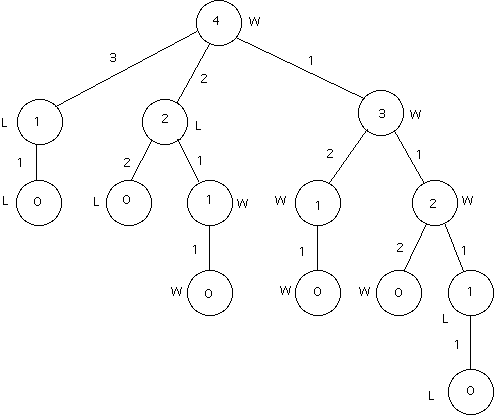
Once the game tree is drawn it is necessary to evaluate it. At terminal nodes the game is over. In Chips this means that there are no chips left in the pile. In that case you know the winner. It is traditional to label the game tree from the point of view of the person making the first move. Therefore a node where the first player wins is labeled "W" and a node where the first player loses is labeled "L".
Once the terminal nodes are labeled you can then evaluate the internal nodes, starting from the bottom of the tree and working to the root (the top node). At even levels (0, 2, 4, ...) the first player moves. It is this player's goal to win the game, so this player always picks the best outcome. That is, he or she will chose a node labeled "W" if one exists. At odd levels (1, 3, 5, ...) the second player moves. This player also wants to win, but that means that the first player looses. Since the tree is labeled from the point of view of the first player the second player chooses a "L" if one exists.
In this manner all nodes in the game tree can be labeled with a W or an L. If the root node is labeled with a W the first player can win, and should chose as his or her moves one that leads to a node labeled W. If the root is labeled L the first player cannot win against best play by the second player, so can pick a move at random or pick a move that will prolong the game as much as possible.
This approach is implemented in the files Chips.java, Game.java, Player.java, HumanPlayer.java, and ComputerPlayer.java. You can download the entire game in Chips.zip.
The Game class records the state of the game. It keeps track of the size of the
pile, the maximum move that can be made by the next player, and two Player objects.
It also keeps track of which player should move next. It provides methods to make a move, test
if the game is over, determine the winner, copy itself, and return various pieces of information
about the state of the game.
Note that Player
is an abstract class, and it keeps track of the player name and the number of chips that a player has
taken. It provides methods to get and update this information. It also requires non-abstract classes that
extend it to implement methods to make a copy of this player object and to get the move to make.
We choose to make each player either a
HumanPlayer (which asks the user for a move)
or a ComputerPlayer (which picks moves using game tree search). This
is why I put the getMove method in the Player rather than
elsewhere. Each player can use a different method of picking a move.
The Chips class supplies the high-level control of the game. It creates the players and
creates the initial Game object. It then enters a loop that continues until the game
is over. In this loop it describes the state of the game, gets a move from the player whose turn
it is to move, and reports the move. When the game is over it prints the final state and the winner.
The rules for this game are a bit different from the one described above. The first player
can take between 1 and n/2 of the chips, and the winner is the one who takes an even number
of chips. However, this program can be changed to last wins by changing a few things in the Game
class. Specifically:
- Change the initial value of
maxMovefromchips/2tochips-1in the constructor - Change the method
getWinnerto use the new rule for deciding the winner - Change the
inputInitChipsmethod to not require the number of chips to be odd.
Everything else is unchanged! (Any guesses for what your last short assignment will be?)
The game tree search is done in the
recursive function pickBestMove. This deceptively simple
function is as follows:
maxMove down to 1.
For each move the function first copies the state of the game
into newState by calling the makeCopy() method.
It then calls newState.MakeMove(move).
This makes the move that is being considered.
After making the move there are two possibilities. If the game is over, then we figure out who wins and return this move if it is a winner for the player currently moving. (Note once the current player finds a winning move there is no reason to search further, so we can just return this winning move.)
If the game is not over, then we call newState.PickBestMove().
This asks for the best move for the opponent, because newState
holds the state of the game after the move was made. If the
opponent has no winning move, then this is a winning move for us and we
return it.
If we exhaust all the moves without finding a winning move then this is a losing position for us and we return 0 to indicate that.
Demo the game computer vs computer (names Computer1 and Computer2).
Problems with complete game tree search for real games
This works fine for Chips with about 30 chips, but if you try it for 100 chips you will wait a long time for the computer to decide its move. This is because the game tree grows exponentially with the number of moves. For a game like chess we could easily write a program to search the entire game tree, but it would not be practical.John McCarthy at Stanford, a pioneer in AI (and once a Dartmouth math professor), defined "computable in theory, but not in practice" as follows. If every atom in the known universe were a computer and it were able to do a computation in the time that it takes light to cross a hydrogen atom and if it began computing at the big bang and were to continue until the projected "heat death" of the universe and it still would not complete the computation, then the computation is not practical. He computed that doing a game tree search for chess is not practical in this sense. Even if an entire game of chess could be evaluated in the time it takes light to cross a hydrogen atom there are so many possible games that the computation would not complete in the projected life of the universe.
So what can we do instead? We look ahead a certain number of moves, and then estimate who is winning. This estimate is called static evaluation. Here "static" means without looking ahead. For chess it would depend on who had more pieces (and more valuable pieces), how mobile the pieces were, how well protected the king was, the pawn structures, and other similar considerations.
There is a tradeoff between doing an accurate static evaluation and depth of lookahead. An accurate but slow static evaluation can be worse than a fast but less accurate evaluation. In the 1970's there was a chess program called Chess 4.2. It incorporated a lot of chess knowledge, but was mediocre in tournaments. Its authors ripped out most of the chess knowledge and concentrated on making it fast and it became national champion, because looking ahead a few moves more useful than having an accurate evaluation of a static position.
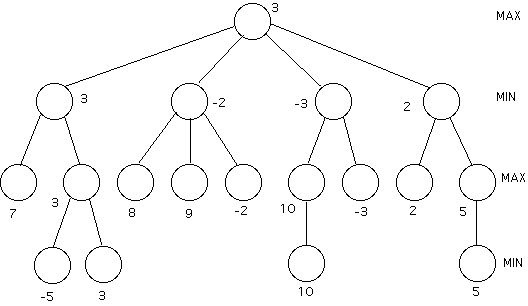
The static evaluation of the game is then used in game tree search evaluation. Instead of just W or L, each node is assigned a number corresponding to the score. In games like go, where you not only win or lose but there is a measure of by how much you win or lose you would use scores in this way even if you evaluated the entire game tree, so that you could find the biggest win. Scores are assigned in terms of the first player. Scores for the second player would be the negative of scores for the first player.
Each terminal node (or node where the look-ahead depth is exhausted) is given a score. On moves where it is the first player's move that player will choose the move to maximize the score. On moves where it is the second player's move that player will choose the move to minimize the score. (Alternatively, the second player can maximize the negatives of the first player's scores.) The following picture shows a game tree for this sort of game, with integer values instead of W and L for values.
This approach of looking ahead a fixed number of moves is not a perfect solution. It works well when the static evaluation function is fairly accurate, but in dynamic situations it often is not that accurate. An example arises in chess. If you capture your opponent's queen that is good, because the queen is the strongest piece. However, if on the next move your opponent captures your queen then you have exchanged queens, which leaves the relative strengths of the two sides approximately where they were before the exchange took place.
However, consider what happens if you are looking ahead 5 moves, and on the last of those 5 moves you capture your opponent's queen. Your opponent will capture your queen on the sixth move, but that is beyond what your lookahead can see. Therefore the situation looks very good, and you might choose a move that leads to this situation rather than one that is in practice a much better move, because it leads to a real rather than an illusionary gain. This problem is called the horizon effect. The bad event of your queen gettting captured is beyond the look-ahead horizon, so it is invisible and for your program does not exist.
It is even worse than this. It may be that it is inevitable that your queen will be captured (perhaps it is pinned or trapped). However, if giving a way a pawn (or a bishop or knight or rook!) pushes the capture over the horizon, your program will begin to behave very irrationally. It will compare the result of losing the queen if it plays normally vs loosing a rook and will decide to sacrifice the rook. But this does not prevent the capture of the queen, so the program will lose the rook and then still have to loose the queen.
To avoid this chess-playing programs try to extend their lookahead depth when the situation is dynamic (pieces in threat of being captured, etc.). The problem with this is that they then can go on looking ahead many moves and run out of time without ever deciding on a move.